Maya - Rigging Framework
Abstract
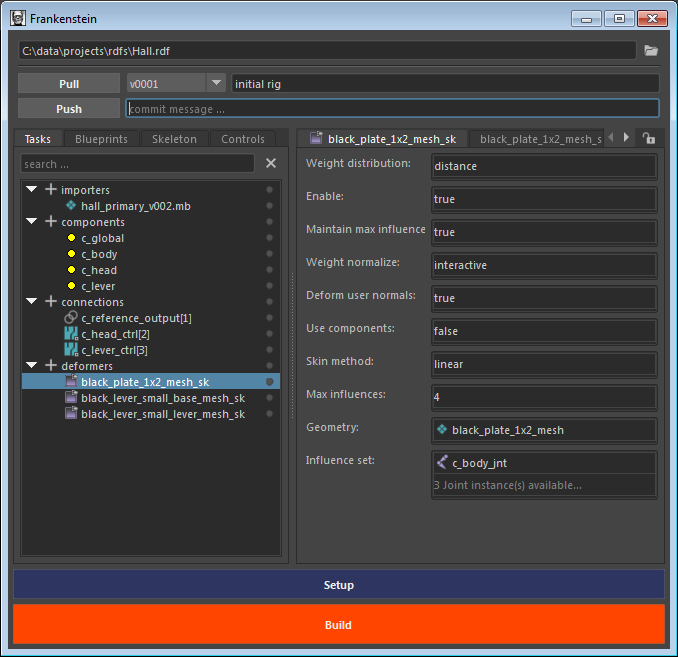
Frankenstein is a modular rigging system developed with Python for Autodesks Maya. At its core it is an object-relational mapping execution tree using an experimental directory structure as its database, tracked using git. The core is separate from the rigging system and is DCC independant to allow for integration with any Python environment.
Introduction
The development of this rigging system came about during the pandemic and sets out to create a system with a strong core developed using a specific set of rules. Django has been a heavy source of inspiration, an extensive set of fields and relations allow for quick iteration and expansion of the system by creating new models that will seamlessly slot into the execution tree. These models interact with an experimental directory structure to read and write their information to and from disk.
Object-relational Mapping
The object relational mapping nature allow extensive linking in the rigging system between the separate models. This will allow for quick debugging as you will be able to see from a control node, which connections, tasks, space switches it is connected to and visa-versa. As all models are initialized together with the data base all (typed) models can be accessed using the class object itself. Fields added to the models at allows for quick customisation and alter behaviour of models through inheritance.
Models
A model can be created by inheriting from a base class. Fields and relations can be added to the class using descriptors. There is a wide variety of fields and relations to choose from. Both fields and relations have base classes that can be inherited from to generate new types.
from frankenstein.core import model
from frankenstein.core import fields
from frankenstein.core import relations
class Joint(models.Model):
side = fields.StringField(default_value="l")
name = fields.StringField(default_value="joint")
index = fields.IntField(null=True, min_value=1)
children = relations.OneToManyRel(rev_name="parent", typed=True)
class Component(models.Model):
side = fields.StringField(default_value="l")
name = fields.StringField(default_value="component")
joint_set = relations.OneToManyRel(Joint, typed=True, hidden=True)
Instances can be created by calling the class create method using keyword arguments. If keyword arguments are provided that are not part of the class an error will be thrown. The same is the case if the provided data is not valid for the created fields.
l_elbow_jnt = Joint.create(side="l", name="elbow")
l_wrist_jnt = Joint.create(side="l", name="wrist", parent=l_elbow_jnt)
l_elbow_jnt = Joint("35d29800-b243-4b4d-bd51-0402ef45557e")
l_elbow_jnt = Joint(l_elbow_jnt.uuid)
Fields
Fields can be retrieved and set using the descriptor. Validators are attached to each field to ensure values can actually be set on the node.
print(l_elbow_jnt.index)
l_elbow_jnt.index = 5
l_elbow_jnt.index = "10" # raises TypeError
Relations
Relations can be retrieved and set using the descripter. Validators are attached to each relation to make sure that only the right typed models are added as relations.
print(l_elbow_jnt.children.all())
print(l_wrist_jnt.parent)
l_wrist_jnt.parent = None
l_elbow_jnt.children.add(l_wrist_jnt)
Managers
Manager objects are attached to the model types and to the relations. Only when a relation is not singular a manager object will be returned. This manager object can be used to Create/Set/Add and Remove model instances.
l_shoulder_jnt = Joint.objects.create(side="l", name="shoulder")
print(Joint.objects.all())
print(Joint.objects.filter(name="wrist")) # operators allowed using '__'
Experimental Directory Structure
The data structure developed for this system has been heavily based on ExDir. The models are linked to directory objects which which allows the fields and relations to store data within this directory. This model data is stored in a JSON file. Fields allow for serialization and deserialization of python objects. In rigging we can work with some very heavy data sets, fields can be classified as such and it will have its data stored in a dedicated file. Heavy time consuming data will only be accessed when needed.
Usage
The directory structure objects are automatically created when instantiating the models, the examples below show how to directly interact with the data structure objects if needed.
from frankenstein.core.storage import directory
# initialize object, create a group and add data
file_object = directory.File("/path/to/directory")
dir_object = file_object.create_group("group")
dir_object.attr["side"] = "l"
dir_object.attr["name"] = "leg"
dir_object.meta["user"] = "rjoosten"
dir_object.data_set["weights"] = [0] * 1000000
# retrieve weights
dir_object = file_object["group"]
weights = dir_object.data_set["weights"]
print(weights)
Hierarchy
Models are identified using a UUID4 key. The key and class information is stored at File level and is used to initialize the entire database without having to parse the entire data structure. Model data is only read from disk once requested, making initialization of the entire database quick.
example.rdf (File, directory)
│ .attributes (Attribute, file)
│
├── 2f5b2d4a-7548-4f4e-86a2-5016bd146492 (Directory, directory)
│ ├── .meta (Attribute, file)
│ ├── .attributes (Attribute, file)
│ └── weights (DataSets, file)
Memory Mapping
As the system works with many separate file they are kept open and memory mapped for quick read and write operations. As only certain amount of files can be kept open a Queueing system is implemented to only allow an X amount of files to remain open. When a new file is requested the last used file will automatically be closed.
Caching
Any data read from disk is cached. This will allow access the its data to be instantanious once read the first time. Caching can be controlled by the user as heavy data sets might want to be wiped to clear it from memory after usage.
from frankenstein.core.storage import directory
file_object = directory.File("/path/to/directory")
file_object.data_set["weights"] # use weights
file_object.data_set.clear_cache() # remove weights from memory
Git
When rig description file is created it automatically sets up a git repository. As all of the files are written in JSON format it makes it an ideal candidate for tracking changes through git. Another benefit is that this repository can be tied to a remote which will allow for a collaborative effort when generating rigs.